Artificial intelligence is beginning to change the way antibodies are discovered. Instead of techniques such as hybridoma technology, phage display, or transgenic mice, researchers can now use computational models to propose new antibody sequences, optimize variable regions, and generate large panels of candidates for experimental testing.
A central requirement in AI-driven antibody discovery is experimental validation.
Computational models can propose antibody candidates, but those sequences still need to be tested experimentally to determine whether they express well, bind the intended target, and show acceptable developability properties. In practice, AI-designed antibodies must be expressed, characterized, ranked, and assessed for potential liabilities before they canbe prioritized for further development.
This is where integrated experimental workflows become important, as AI-based discovery depends on generating high-quality experimental data that can confirm candidate performance and feed those results back into the discovery process.
The Design–Build–Test–Learn Cycle
First, candidate antibody sequences are designed, often using computational or machine learning methods. Next, those sequences are built by expressing the antibodies in cells. The resulting molecules are then tested for properties such as expression, binding affinity, stability, polyreactivity, and self-interaction. Finally, the resulting data are incorporated back into the model or discovery workflow to inform the next round of design.
In AI-driven discovery, this feedback loop determines which designs are performing well, which are not, and what sequence or biophysical features may explain those outcomes.
One difficulty is that wet-lab workflows may not scale at the same rate, since traditional antibody expression and characterization often involve separate workflows for expression, purification, binding analysis, and developability assessment.
In that sense, progress in AI-based antibody discovery may depend not only on generating more candidate sequences, but also on improving the quality and speed of experimental feedback.
Early Developability Assessment is Becoming Increasingly Important
An antibody that binds strongly to its target may still be difficult to manufacture, unstable, or prone to nonspecific interactions. Identifying these issues early can reduce time spent advancing candidates that perform well in a binding assay but are less suitable as therapeutic leads.
For that reason, integrated workflows that combine expression, binding characterization, analytical quality assessment, and developability profiling into structured datasets can be used directly in downstream analysis or model retraining.
Biointron’s RushData platform, for example, is intended to convert AI-designed antibody sequences into expressed antibodies, multidimensional assay data, and structured outputs for model feedback. The platform combines 1-day CHO expression, rapid affinity characterization, and developability profiling, with the aim of producingAI-ready antibody datasets in days rather than weeks.
1-Day CHO Expression for Antibody Characterization
Chinese hamster ovary, or CHO, cells are preferred in biopharmaceutical antibody production, owing to their capacity to facilitate appropriate protein folding and perform accurate post-translational modifications (PTMs). Nearly70% of approved recombinant therapeutic proteins are produced in CHO systems.Their widespread use reflects several advantages:
· Growth in serum-free suspension culture, which supports scalable bioprocessing
· Lower susceptibility to human viruses than human cell lines
· Stable transgene integration
· Capacity for complex protein folding and secretion
· Ability to perform many mammalian PTMs relevant to therapeutic protein quality
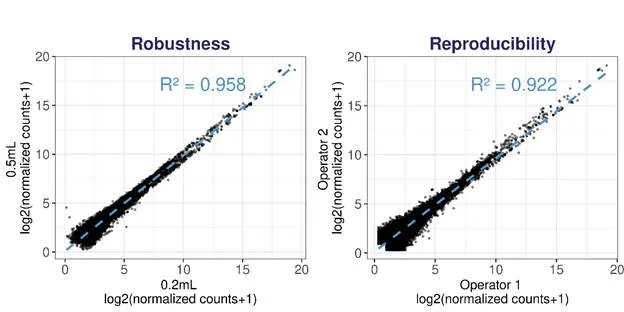
Since AI-enabled programs increasingly require standardized, scalable data generation, RushData is ideal in that it can evaluate thousands of candidates in parallel, with capacity for more than 3,000 molecules per batch, and can include BLI or SPR binding characterization, DSF thermal stability analysis, PSR-BVP polyreactivity assessment, and AC-SINS self-interaction analysis.
More broadly, platforms such as RushData reflect the direction of data-driven antibody engineering, where machine learning and high-throughput experimentation are increasingly coupled in an iterative workflow. In this framework, experimental systems do more than validate computational predictions:they generate the sequence, binding, and biophysical data needed to refine models and support subsequent rounds of design. As antibody discovery becomes more data-driven, the ability to produce structured, multidimensional datasets at scale may be as important as the predictive models themselves.
About Biointron
Founded in 2012 and certified to ISO 9001:2015, Biointron is a CRO specializing in antibody discovery, expression, and optimization services for biotech and pharmaceutical companies. From gene sequence to purified antibodies, our production only takes 2 weeks — and with RushData, our AI antibody wet lab validation service, computational predictions become experimentally confirmed candidate sat high throughput. We have delivered tens of thousands of recombinant antibodies for more than 3,000 biotech and pharma companies worldwide.
Take the Next Step
Explore Suppliers
Browse trusted partners with relevant expertise
Review Capabilities
Compare services, experience, and past work
Start Your Project
Connect and begin collaborating
.png)