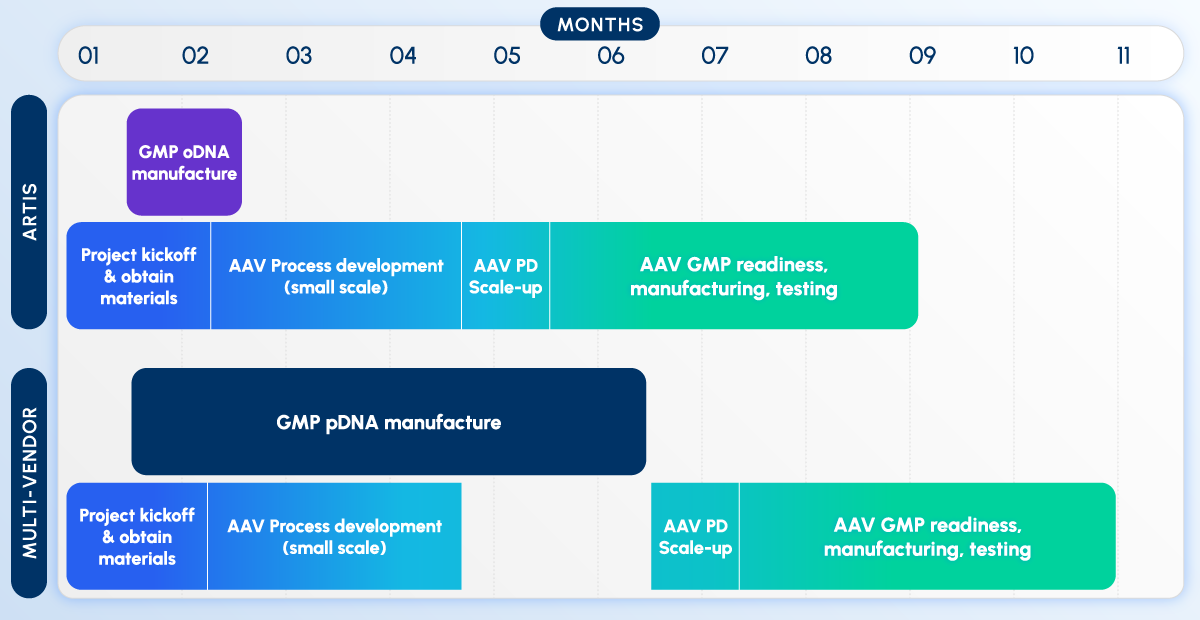
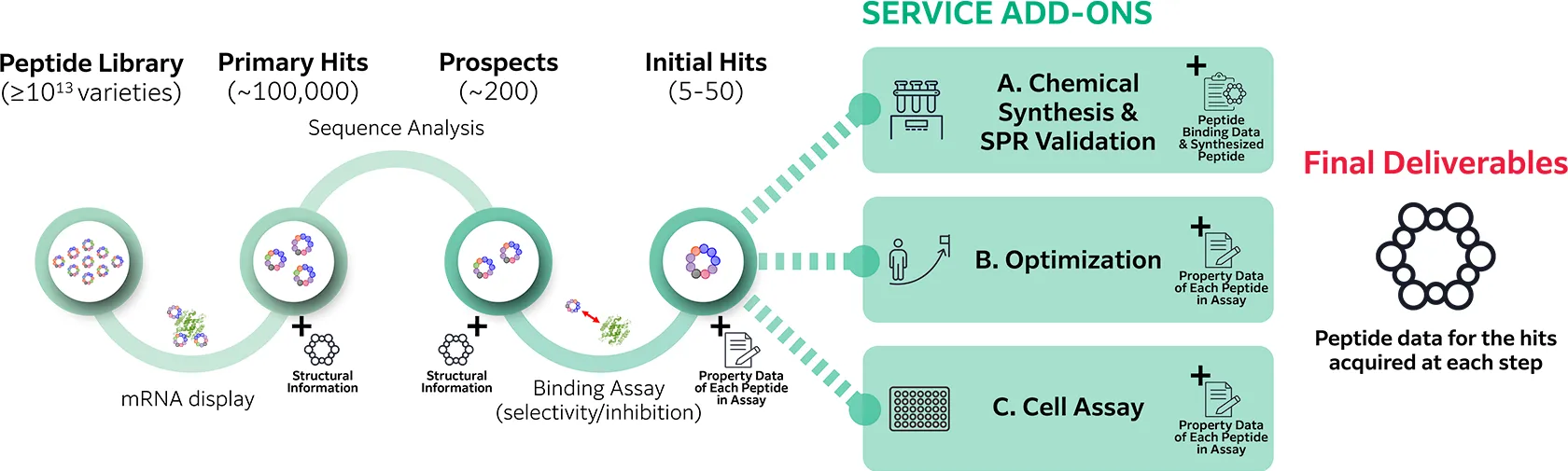
RAG pipelines are becoming the backbone of LLM-based applications — but how do you build one that actually works in production?
In this talk, Chris Petersen, Co-founder and CTO of Scientist.com breaks down the end-to-end architecture of a modern RAG system: chunking, search (BM25 + vectors), query rewriting, HyDE, reranking, repacking, tool calling and summarization. It’s a practical, modular approach informed by research and grounded in real-world experience building AI systems at scale.
Take the Next Step
1
2
3
Explore Suppliers
Browse trusted partners with relevant expertise
Review Capabilities
Compare services, experience, and past work
Start Your Project
Connect and begin collaborating




.png)